Kvantitativ analyse av aviser
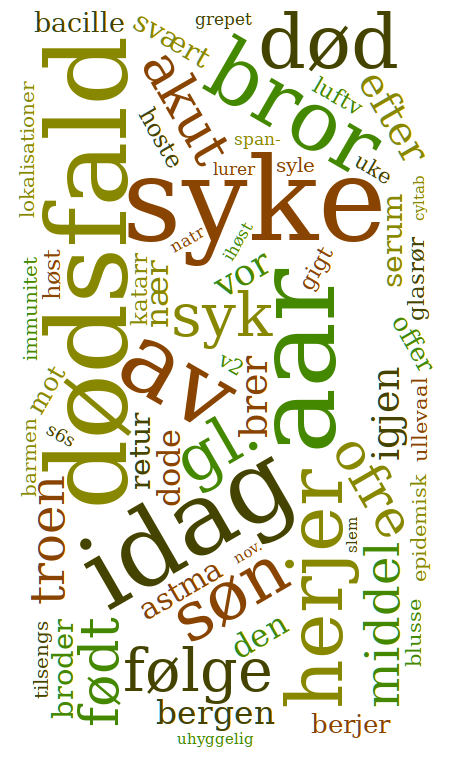
Du kjenner det ganske sikkert fra et Google-søk: Når du søker opp et ord, får du små snutter med tekst som viser eksempler på kontekster søkeordet brukes i. Disse hjelper oss i å finne frem til riktig nettsted. Men slike tekstutdrag, eller konkordanser som de også ofte kalles, kan også brukes mer systematisk i statistisk analyse. Ved å telle alle ordene i tekstutdragene, kan man danne seg en idé om hvordan søkeordet blir brukt. Den engelske språkviteren John Rupert Firth sa en gang: «You shall know a word by the company it keeps» – et ords betydning åpenbarer seg i konteksten. For eksempel vil ord som land og monarki dukke høyt opp på listen hvis man søker på Norge og teller ord som forekommer sammen med Norge i disse tekstbitene, rett og slett fordi dette beskriver sentrale egenskaper ved ordet Norge.
Ikke alle ord er imidlertid like interessante: Norsk har mange funksjonsord som binder ord sammen med hverandre og som kan være mindre informative. Derfor sammenlikner vi resultatene vi får fra tekstbitene med en referanse (f.eks. alle ordene i avisene trykket i et gitt tidsrom). Gitt at ordet dødsfall forekommer ti ganger oftere sammen med spanskesyken enn i referansen, kan dette tyde på en nær forbindelse mellom de to ordene. Og dette stemmer: Spanskesyken tok svært mange liv. Det finnes ulike måter å beregne styrken av slike assosiasjoner på. I denne presentasjonen brukes såkalt pointwise mutual information. Du kan lese mer om dette på engelsk her, hvis du vil gå dypere inn i materien.
Dette målet brukes i ordskyene: Jo større et ord i ordskyen er, desto sterkere er det forbundet med ord som refererer til en bestemt epidemi.