8–9
mai
«Literary Networks and Networks in Literature». Konferanse
Starter:
Onsdag 8. mai 2019, kl. 00:00
Avsluttes:
Torsdag 9. mai 2019, kl. 23:59
Nasjonalbiblioteket
Nettverk finnes overalt, også i fiksjonens verden. Dataassistert analyse av relasjoner mellom litterære karakterer har pløyd ny mark i litteraturstudier. Samtidig representerer det litterære feltet med sine aktører et spennende forskningsfelt i seg selv. Litterær nettverksanalyse peker dermed i to retninger: Den ene varianten retter seg mot tekster, den andre undersøker det litterære feltet som et sosialt nettverk. Et knippe eksperter fra Europa og Nord-Amerika er invitert for å belyse bruk av nettverksanalyse i studier av litteratur.
Innlegg ved: Katrin Dennerlein (University of Würzburg), Lieve van Hoof (Ghent University), Matthew Wilkens (University of Notre Dame), Mark J. Hill (University of Helsinki), Lars Johnsen (Nasjonalbiblioteket), Karen Arup Seip (Nasjonalbiblioteket), Jens-Morten Hanssen (Nasjonalbiblioteket). Konferansen foregår på engelsk.
Location: Store Auditorium
10.00 am: Welcome
10.10 am: Kathrin Dennerlein, Networks of Dramatic Texts
10.40 am: Matthew Wilkens, Networks of Place
11.10 am: Lars G. Bagøien Johnsen, Constructing Word Networks from Books
12.00: Lunch
1.00 pm: Jens-Morten Hanssen, Name-Dropping in Literary History
1.30 pm: Lieve Van Hoof, Networks in Libanius, and Libanius in Networks
2.00 pm: Coffee Break
2.15 pm: Mark J. Hill, The ESTC and Long-18th Century Book Trade Networks
2.45 pm: Karen Arup Seip, Christiane Koren – A Study in Sociability
3.15 pm: Concluding Remarks
Location: Halvbroren, Møterom 30
9.15 am – 3.45pm: Lars G. Bagøien Johnsen and Yngvil Beyer, Workshop on Computational Network Analysis
Sign up for the workshop by sending an e-mail to dh-workshop@nb.no by May 3.
Kathrin Dennerlein (University of Würzburg): Networks of Dramatic Texts
While literary history is usually conceived as a linear series of works in a single language this paper shall point the view to the complexity of the literary field and its history. The copresence of new releases and classical works, of different versions and formats of single works and the communicative acts which make them matter are to be conceptualized. Networks and Stemmata shall be proposed to cope with this new abundance of material. The main part of the paper shall show by way of example how the history of dramatic texts from 18th century Germany may be accessed through these concepts.
Matthew Wilkens (University of Notre Dame): Networks of Place
Geographic space is a key element of literary texts. Spatial information helps to establish narrative settings, shape social connections between characters, and define political links between communities. This paper analyzes the network relationships between geographic entities in more than 100,000 volumes of English-language fiction published in the United States and Great Britain between 1800 and 2010. It includes special emphasis on historical patterns of spatial attention to Scandinavian locations and on differences associated with author gender and national origin.
Lars G. Bagøien Johnsen (National Library of Norway): Constructing Word Networks from Books
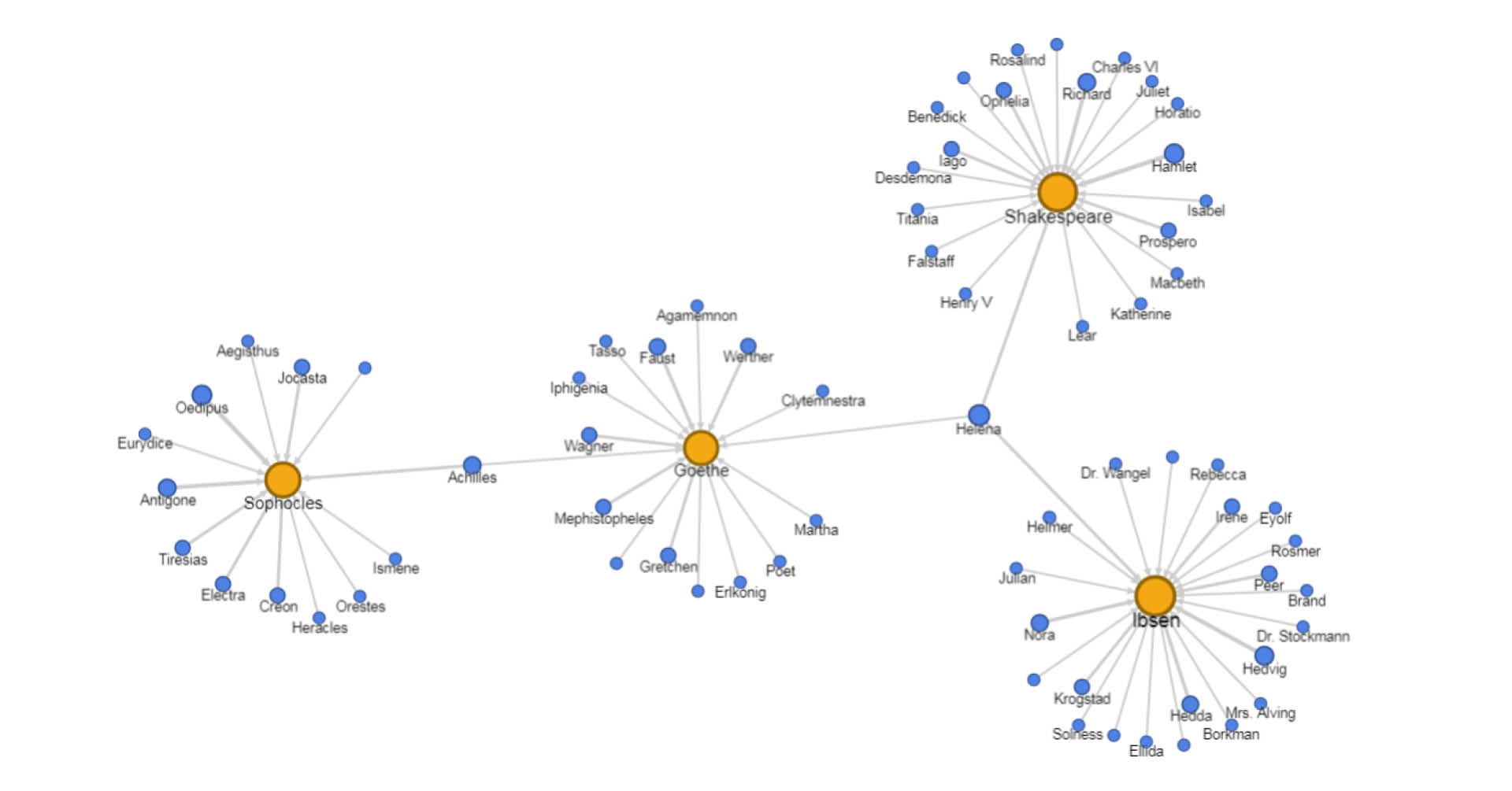
The digital archive of the National Library of Norway has made approximately 500,000 books available for distant reading, which means that certain features of the books can be extracted and studied. One of those features may be a word or phrase network. In this presentation I will show how a two-way information extraction makes it possible to make name and place networks from books.
One way goes from words and phrases to graphs. From any given list of words, a graph can be extracted from a book where each node is a word or phrase, connected by an edge if the two words (phrases) occur together within the same paragraph. The other way consists of commands that analyse words within a book according to principles of NER (Name Entity Recognition), tuned so that it returns a set of person names, place names and works. The sets extracted from the NER algorithm can be edited and the result fed back to the book in order to create a graph (network) of persons, places and works.
Jens-Morten Hanssen (National Library of Norway): Name-Dropping in Literary History
Literary history is not only a discipline, but also a genre with its own literary and stylistic conventions. A literary history typically contains a myriad of names of persons, places, and literary works. These names are key elements of the literary historians’ narratives. I will present a project of examining a corpus of more than two hundred book-length accounts of Norway’s literary history from the digital collection of the National Library of Norway. Drawing on the library’s digital research infrastructure, I use Named Entity Recognition to extract names from the texts, collocation analysis and network analysis to identify deep structure patterns and connections across the texts.
Lieve Van Hoof (Ghent University): Networks in Libanius, and Libanius in Networks
Letter collections have been amongst the most fruitful sources used to carry out historical network analysis (e.g. McLean 2007). Yet barring few exceptions (e.g. Alexander & Danowski 1990, Schor 2007), most ancient collections still await exploration from this point of view. This paper reflects on the potential and challenges involved in applying social network analysis to ancient letter collections. In order to do so, it uses the letters of Libanius of Antioch (A.D. 314-393) as a case study.
Mark J. Hill (University of Helsinki): The ESTC and Long-18th Century Book Trade Networks
This paper offers and overview of research into the use of the English Short Title Catalogue (ESTC) as a type of historical dataset which is capable of providing insights into the historical social networks which made up the early modern book trade. It offers an overview of the methods used, with specific emphasis on the importance of metadata cleaning, harmonization, and processing, as well as initial analyses demonstrating the use of the dataset when identifying historically relevant author clusters, actor centrality, and distinguishing between networks covering initial editions of a work and reprints.
Karen Arup Seip (National Library of Norway): Christiane Koren – A Study in Sociability
Christiane Koren came to Norway in 1787, without any other resources than a fortunate marriage, an eagerness to write and a talent for sociability. Here she became the centre in a group of literary interested people, the Hovind circle. This paper is telling the story of how she linked people around her more closely by giving her friends roles as children and sisters, opening up her home for them and circulating her diaries among them. In much of the network literature, women only appear as passive actors through their roles as marriage partners that bind together networks, so it is interesting to study a woman who herself took an active role as a network builder.
Lars G. Bagøien Johnsen and Yngvil Beyer (National Library of Norway): Workshop on Computational Network Analysis
The workshop introduces novices to the basics of computational network analysis. We will use the programming language Python and Jupyter Notebook as our interactive working environment. The data set is created from the digital collection of the National Library.